Medtrack: Part One
This will be a multiple part series (I haven't decided how many parts yet) where I dump my ideas each weekend on my ongoing side project Medtrack.
Disclaimer: Some of the ideas, tech, design choices introduced here might not survive to the final prototype, my approach is a trial and error approach: I choose a tool or an idea and I push it to the limit, if it doesn't serve the solution well I drop and I look for something else.
I got bored one day and I figured I could make a project to solve a problem and at the same time hone my development skills.
The problem
The problem this project solves is the following: many people use medication everyday, and of course they have to read the leaflet inside as adviced, the leaflet is usually unreadable, the font is super small and you keep looking for your answer in a pile of tiny characters. So the human in our case is fed up with this and in our current year he takes out his phone, he snatches a picture of the front of the drug, and he follows it up with a prompt to the LLM to get his answer (maybe he wants to know the dosage if he forgot it). I myself I'm guilty of this and I asked Mr.chatgipiti for answers to survive.
But there's so many issues here:
- LLMs are generalizers, they are not trained to specifically perform this task
- LLMs generate probabilistic answers (may hallucinate)
- LLMs upload user data to massive servers (huge privacy risk, as this is medical info).
- LLMs might “search the web” vaguely to look for answers (they might fetch from untrusted sources)
These are the issues I can think of right now, but it could be more.
The solution
Since we established the issues related to LLMs for this kind of task, let me introduce my humble solution for this task:
-
The medical information will be fetched from a credible source (I'm thinking on openFDA)
-
The medical information won't be sent to some black box server where you don't know what you data will be used for, the models I'm using are local:
- I will be using a local OCR (Optical character recognition) model to extract textual data from the picture of medication uploaded by the user. I'm thinking on Tesseract OCR through it's Python interface pytesseract or EeasyOCR.
- Since the OCR model won't know exactly what kind of data I find useful, I will use another local model in addition to OCR, to return the exact information I need. I'm thinking on an LLM from OLLAMA.
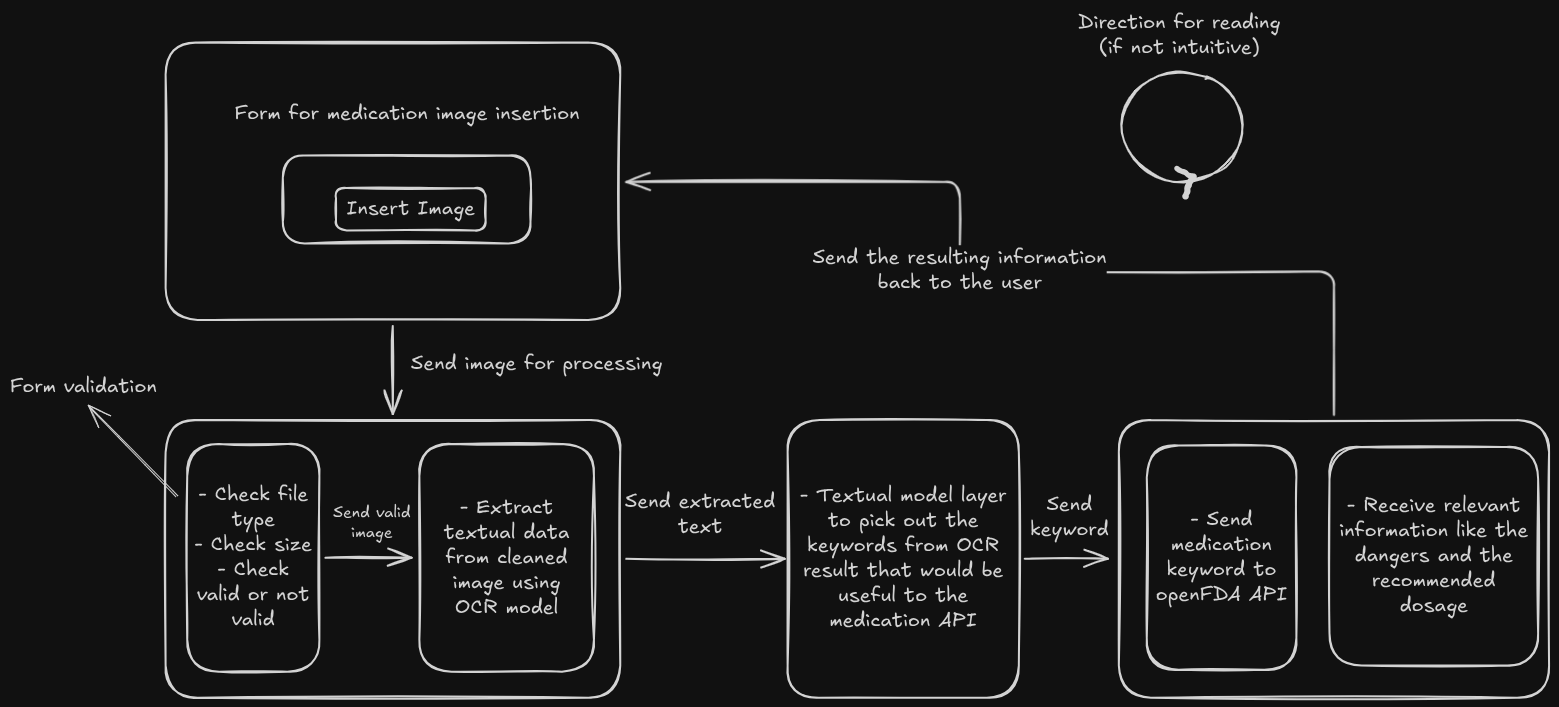
Some people would say, since you are using a local model from OLLAMA, why don't you use a local LLM from OLLAMA and stop the headaches? To that I will answer, not everybody has that kind of compute to run a respectable LLM with enough parameters, and also we still have the hallucination problem.
That's it, I will sure add some info in the future, update this post, add some other post, yeah seeya.