Medtrack
Caution
Medical Disclaimer: This project is for educational and technical demonstration purposes only. The information provided by the AI should not be used for medical diagnosis, treatment, or as a substitute for professional medical advice. Always consult a healthcare professional for medication concerns.
Note
This project was built as a personal exploration to experiment with new technologies and does not represent a production-ready medical tool.
My approach to delivering software prototypes is a trial and error approach: I choose a tool or an idea and I push it to the limit, if it doesn't serve the solution well I drop and I look for something else.
I got bored one day and I figured I could make a project to solve a problem and at the same time hone my development skills.
The problem
The problem this project solves is the following: many people use medication everyday, and of course they have to read the leaflet inside as adviced, the leaflet is usually unreadable, the font is super small and you keep looking for your answer in a pile of tiny characters, sometimes you only have the medication but you have lost the package and leaflet. So the human in our case is fed up with this and in our current year he takes out his phone, he snatches a picture of the front of the drug, and he follows it up with a prompt to the LLM to get his answer (maybe he wants to know the dosage if he forgot it). I myself I'm guilty of this and I asked Mr.chatgipiti for answers to survive.
But there's a clear issue of privacy here:
LLMs upload user data to massive servers (huge privacy risk, as this is medical info).
The solution
Since we established the issues related to LLMs for this kind of task, let me introduce my humble solution for this task:
-
The medical information won't be sent to some black box server where you don't know what you data will be used for, the models I'm using are local:
- You will be using a local OCR (Optical character recognition) model to extract textual data from the picture of medication uploaded by the user: PaddleOCR.
- On top of the OCR layer for extracting textual data from pictures of medication taken by the user with their smartphone, we need to send that stream of extracted data to a local textual model (text-in-text-out) to return the relevant information by making sense of the content of the picture: A Small Language Model (I used LLama3.2:3B) ran with Ollama.
The flow of the app
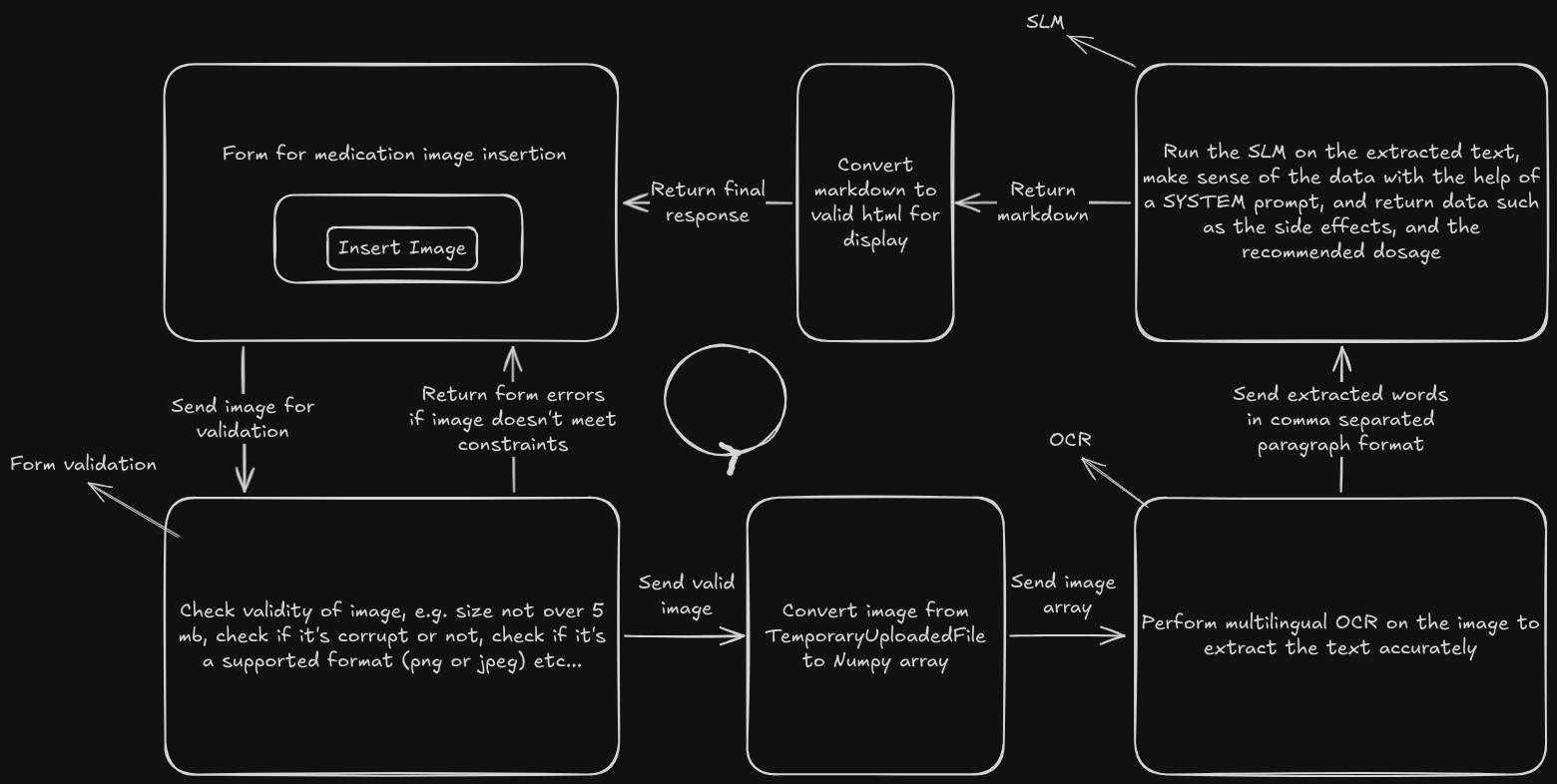
PaddleOCR

PaddleOCR provides many options for processing:
- You can set the maximum length of the picture
- You can set an option that flattens the picture if the user input picture is a round medication
- You can set an option that classifies if the picture is rotated and it rotates back to normal to process it
this is just a small sample of options and there's more.
Initial plan for the app
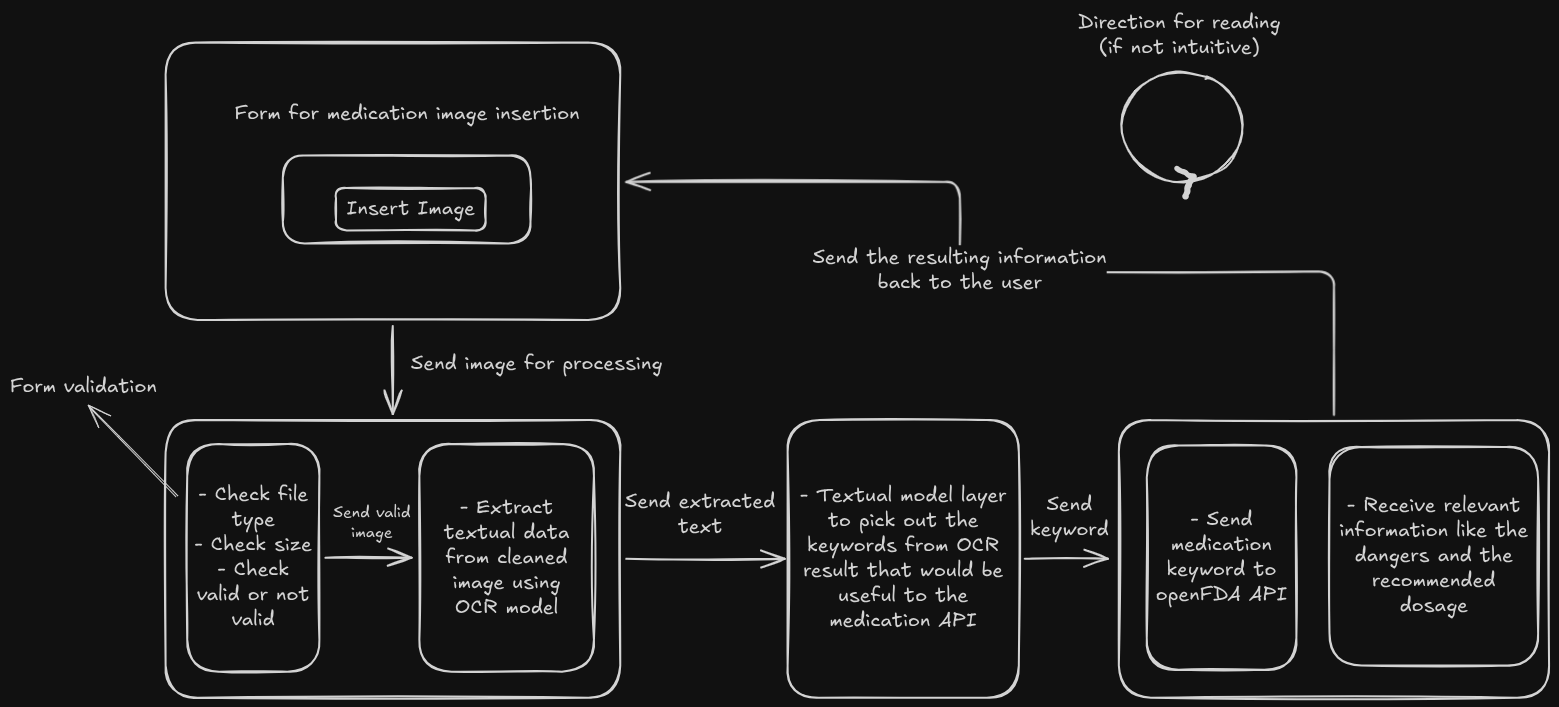
- OCR extraction
- SLM extracts the data that I need
- Send keyword or medication brand name to OpenFDA API
I dropped OpenFDA API halfway through the project.
Hardware
- The pre-configured PaddleOCR model in the source code runs entirely using the cpu and is very lightweight, any modern pc with the bare minimum hardware can run it no problem
- The SLM layer requires some hardware but not that much, I got by using only my 4gb VRAM gpu it let's me run up to 4B parameters language models. When choosing which local model to choose check this page
Big Realizations
Half way through building the project, I started noticing some issues that are related to core components that are reliable for the app to function correctly:
OpenFDA unpredictable JSON response
Initially when I was researching and didn't start development yet I eyed openFDA as my primary source of information regarding medical data, but after some tests in the development phase I noticed that the responses from OpenFDA are inconsistent. Some drug names return certain fields like usability and some don't include it at all which creates a lot of issues. While I can resolve this issue and incorporate some logic to emit some fields in favor of others, it wasn't worth it in my opinion.
SLMs are very dumb
Having never worked with language models locally I had no idea what to expect. But after some test use cases it became very clear: Don't expect much from these small models. The level of reasoning between modern age LLMs and local small to medium sized langauge models is astronomical, in terms of reasoning and even in basic understanding. Small langauge models hullucinate way more often.
Using AI to get medical info is not a good idea
Even with "smarter" models the hullucination problem is very critical, and some people rely confidently on these models for answers. I was very aware of that, that's why at the beginning I chose openFDA for a consisten stream of data instead of AI-generated text.
Conclusion
While this project is not very practicle in a real world scenario, it enabled me to learn new technologies, and how to incorporate modern dev tools, even though the use case is not that useful for human consumption.
Once I lost interest in the idea I stopped working on the project, this post is an example as I wrote it in 30 or so minutes (aplogies for any mistakes).